Typical layout-to-image synthesis (LIS) models generate images for a closed set of semantic classes, e.g., 182 common objects in COCO-Stuff.
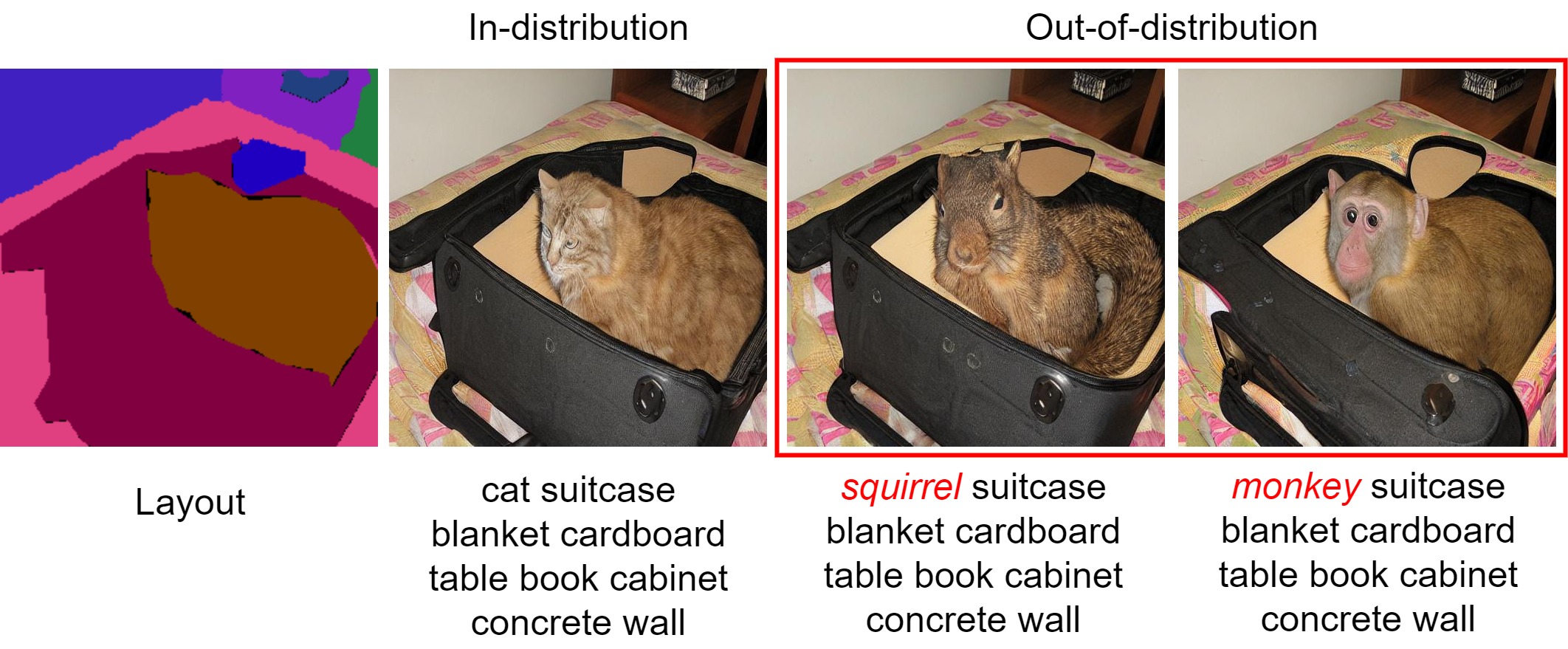
In this work, we explore the freestyle capability of the model, i.e., how far can it generate unseen semantics (e.g., classes, attributes, and styles)
onto a given layout, and call the task Freestyle LIS (FLIS). Thanks to the development of large-scale pre-trained language-image models,
a number of discriminative models (e.g., image classification and object detection) trained on limited base classes are empowered with
the ability of unseen class prediction. Inspired by this, we opt to leverage large-scale pre-trained text-to-image diffusion models
to achieve the generation of unseen semantics. The key challenge of FLIS is how to enable the diffusion model to synthesize images from
a specific layout which very likely violates its pre-learned knowledge, e.g., the model never sees "a unicorn sitting on a bench" during
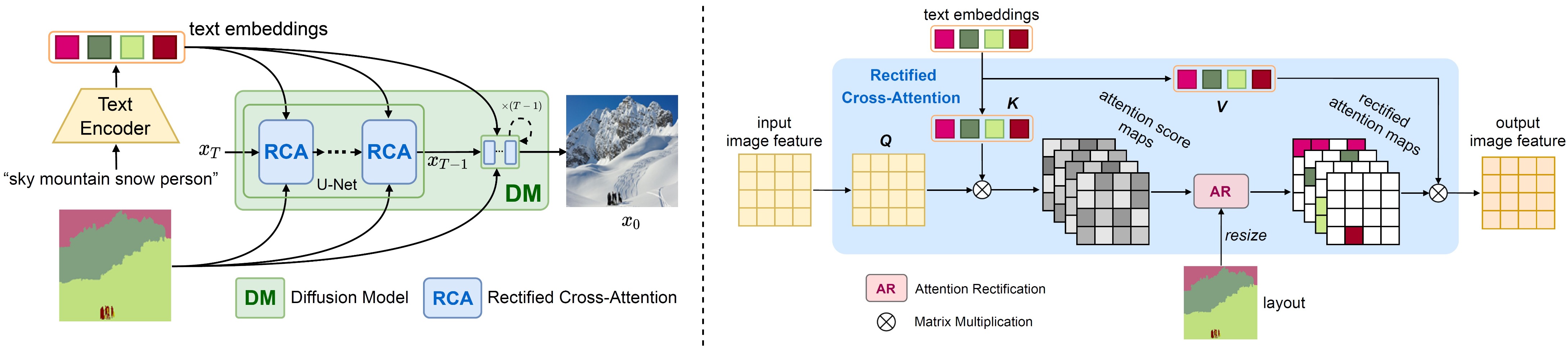
its pre-training. To this end, we introduce a new module called Rectified Cross-Attention (RCA) that can be conveniently plugged in the diffusion model
to integrate semantic masks. This "plug-in" is applied in each cross-attention layer of the model to rectify the attention maps
between image and text tokens. The key idea of RCA is to enforce each text token to act on the pixels in a specified region,
allowing us to freely put a wide variety of semantics from pre-trained knowledge (which is general) onto the given layout (which is specific).
Extensive experiments show that the proposed diffusion network produces realistic and freestyle layout-to-image generation results
with diverse text inputs, which has a high potential to spawn a bunch of interesting applications.